✧ Lean-Based Formal Verification Research
Lean4Formal VerificationPost Training: SFT and GRPOChain-of-Thought
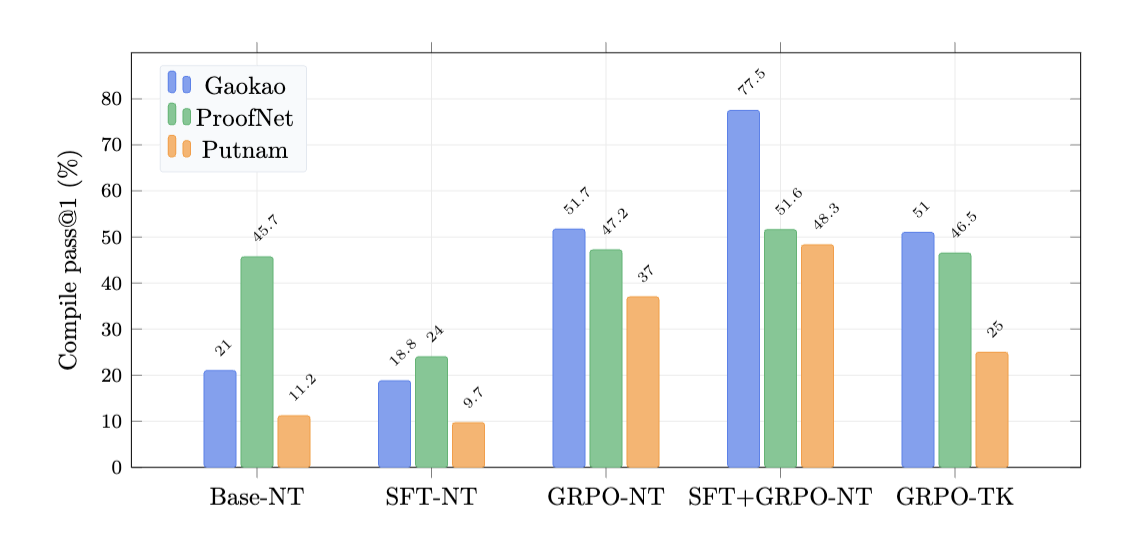
Conducting independent research in Lean 4 autoformalization, training an 8B-parameter model that achieves 2.6x the formal proof accuracy of its base model across four competition-level math benchmarks.
Built a full RL pipeline from scratch--data curation, SFT priming, GRPO training, and a compile-and-judge evaluation harness--on self-managed Kubernetes clusters.
Publishing findings as a technical report with open-source model weights, datasets, and training infrastructure.